Technik Crawler Einstellungen: Mögliche Probleme & Lösungen
1. Technik Crawler individuell anpassen
Sie können den Technik-Crawler individuell an Ihre Bedürfnisse anpassen. Die Einstellungsmöglichkeiten finden Sie hier: https://osg-ps.de/technical-crawler-crawl-settings.
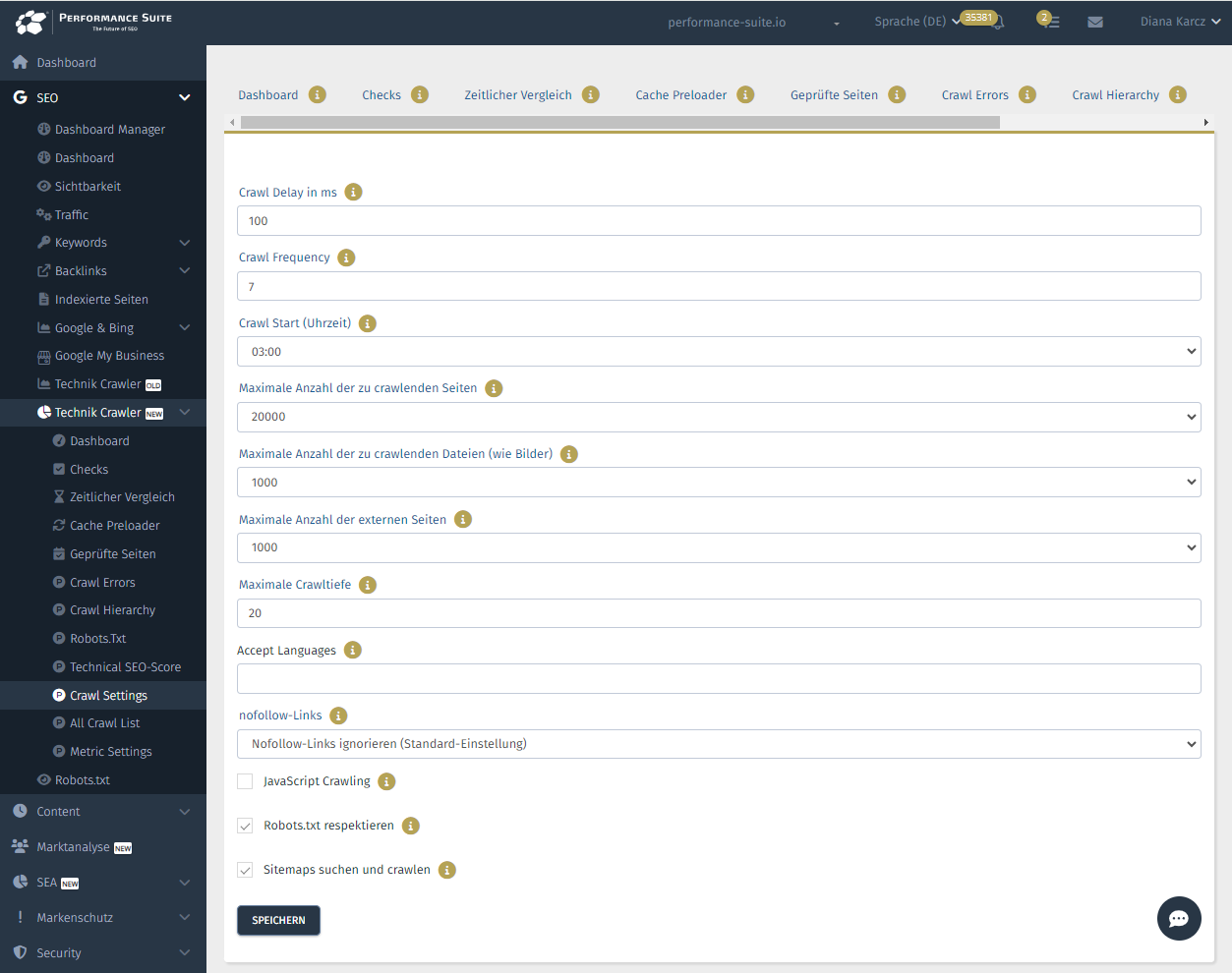
Technik Crawler Einstellungen unter https://osg-ps.de/technical-crawler-crawl-settings
Folgende Einstellungen können Sie vornehmen:
- Crawl-Delay in ms: Der Crawl-Delay teilt dem Crawler mit, wie viel Zeit dieser zwischen aufeinanderfolgenden Anfragen an den Server warten sollen. Beispiel: Bei einem Crawl-Delay von 300ms, muss der Crawler 300ms warten, bevor er eine neue Anfrage an den Server sendet. Bei einem Crawl-Delay von 300ms kann der Crawler kann ungefähr 3,33 Anfragen pro Sekunde und 11.988 pro Stunde stellen. Das Erhöhen des Crawl-Delays ist sinnvoll, um die Serverlast zu reduzieren und die Leistung der Website zu verbessern, insbesondere bei begrenzten Server-Ressourcen oder während Zeiten mit hohem Traffic. Ein zu niedrigen Crawl-Delay kann zu Down-Times führen, wenn Ihr Server zu viele Abfragen in kurzen Abständen nicht verarbeiten kann. Für viele Websites ist ein Delay von 100 bis 300 ms problemlos möglich.
- Crawl Frequency: Hier können Sie angeben, wie oft Ihre Website gecrawlt werden soll. Bei einer Crawl-Frequenz von 7 wird Ihre Website alle 7 Tage automatisch neu gecrawlt. Wenn Sie viele Änderungen auf Ihrer Website umsetzen, können Sie auch manuell jederzeit ein neues Crawling starten.
- Crawl Start (Uhrzeit): Geben Sie an, um wie viel Uhr der Crawler starten soll. Um den Server nicht zu überlasten, sollte der Crawl um eine Uhrzeit starten, an der sonst keine anderen umfangreichen Abfragen an den Server geschickt werden, um diesen nicht zu überlasten. Wenn Sie z.B. einen Shop betreiben und automatisch um 02:00 Uhr neue Produkte in Ihren Shop geladen werden, sollte der Crawler nicht parallel laufen. Empfohlen wird eine Uhrzeit zwischen 00:00 und 06:00 Uhr, da hier in der Regel wenig Traffic herrscht.
- Maximale Anzahl der zu crawlenden Seiten: Geben Sie die maximale Anzahl der zu crawlenden Seiten an. Sie können bis zu 100.000 Seiten crawlen.
- Maximale Anzahl der zu crawlenden Dateien (wie Bilder): Geben Sie die maximale Anzahl der zu crawlenden Dateien an. Das sind z.B. Bilder und PDFs.
- Maximale Anzahl der externen Seiten: Geben Sie die maximale Anzahl der externen Seiten an. Das sind z.B. Links, die auf andere Domains führen.
- Maximale Crawltiefe: Die Crawltiefe (maximal depth) bestimmt, wie viele Klicks eine Seite von dem Startpunkt des Crawlers (in der Regel die Startseite) entfernt ist. Eine Crawltiefe von 20 bedeutet, dass der Crawler bis zu 20 Klicks tief in die Website-Struktur eindringen kann. Eine Crawltiefe von 20 ermöglicht ein sehr umfassende Crawling Ihrer Domain, um auch tief verlinkte Inhalte zu finden. Beachten Sie, dass eine hohe Crawltiefe Auswirkungen auf Crawling-Zeit und Ihre Serverlast haben kann, da ggf. mehr URLs gefunden werden können.
- Accept Languages: Der „Accept-Language“-Header in den Einstellungen teilt dem Crawler mit, in welchen Sprachen der Crawler die Inhalte bevorzugt abrufen soll. Dadurch wird beim Crawling sichergestellt, dass mehrsprachige Websites in den gewünschten Sprachen durchsucht werden, um die relevantesten Inhalte zu erfassen. Sie können z.B. angeben, dass Inhalte in Deutsch (de) oder Englisch (en) bevorzugt gecrawlt werden sollen.
- nofollow-Links: Geben Sie an, ob der Crawler Links mit nofollow-Attribut folgen soll. Standardmäßig wird nofollow-Links nicht gefolgt.
- JavaScript Crawling: Hier können Sie das JavaScript-Crawling aktivieren. Das Crawlen mit JavaScript verlängert die Crawling-Dauer erheblich und ist nur für Websites notwendig, die Inhalte dynamisch per JavaScript ausliefern oder nachladen.
- Robots.txt respektieren: Die Robots.txt gibt Anweisungen darüber, welche Teile Ihrer Website von Crawlern besucht werden dürfen und welche nicht. Hier können Sie angeben, ob der Crawler Ihre robots.txt Angaben respektieren oder ignorieren soll. Die Einstellung respektieren wird empfohlen.
- Sitemaps suchen und crawlen: Mit dem Crawlen der XML-Sitemaps kann überprüft werden, ob Seiten in der Sitemap indexierbar sind, ob wichtige Seiten fehlen und ob Fehler in der Sitemap vorhanden sind. Diese Funktion erleichtert die gezielte Optimierung und stellt sicher, dass alle relevanten Seiten korrekt erfasst und indexiert werden können. Es wird empfohlen, die Sitemaps zu prüfen.
2. Crawl-Probleme & Lösungen
2.1 Serverprobleme aufgrund des Crawlers
Wenn der Crawler Serverprobleme verursacht, wie z.B. eine hohe Serverlast oder Downtimes, können folgende Maßnahmen helfen:
Wichtige Einstellungen
- Crawl-Delay anpassen: Erhöhen Sie den Crawl-Delay (z.B. von 100ms auf 300ms oder 500ms), um die Anfragenlast auf den Server zu reduzieren. Je höher der Delay, desto länger dauert der Crawl, aber desto geringer ist die Belastung des Servers.
Wenn Serverprobleme weiterhin auftreten, passen Sie die folgenden drei Kriterien Schritt für Schritt an:
- Crawl Delay: Erhöhen Sie den Delay schrittweise (z.B. von 100ms auf 300ms oder 500ms). Je höher der Delay, desto geringer die Serverlast, aber die Crawling-Dauer verlängert sich.
- Maximale Crawltiefe: Verringern Sie die Crawltiefe, um weniger tief in die Website-Struktur vorzudringen. Dies reduziert die Anzahl der zu durchsuchenden Seiten und damit die Serverlast.
- JavaScript Crawling: Aktivieren Sie JavaScript Crawling nur, wenn es unbedingt notwendig ist, da dies die Crawling-Dauer und die Serverbelastung erheblich erhöhen kann.
Weitere Einstellungen
- Crawling-Zeitfenster anpassen: Starten Sie den Crawler zu Zeiten mit geringem Traffic (z.B. zwischen 00:00 und 06:00 Uhr), um die Belastung zu minimieren.
- Maximale Anzahl der Seiten reduzieren: Verringern Sie die Anzahl der zu crawlenden Seiten oder Dateien, um die Serverbelastung zu senken.
2.2 Der Crawler findet zu wenige URLs
Wenn der Crawler zu wenige URLs findet, kann dies an verschiedenen Einstellungen liegen. Gehen Sie folgendermaßen vor:
Wichtige Einstellungen
- Crawl-Probleme aufgrund Serverfehler: Der Crawler wird ggf. von ihrem Server gesperrt, weil zu viele Abfragen erfolgen. Beachten Sie hierzu die Anweisungen zu „Serverprobleme aufgrund des Crawlers“.
- Maximale Crawltiefe erhöhen:
- Überprüfen Sie die eingestellte Crawltiefe. Wenn die Tiefe zu niedrig ist, findet der Crawler nur oberflächliche Seiten.
- Erhöhen Sie die Crawltiefe schrittweise (z.B. von 3 auf 20), um mehr verlinkte Inhalte zu finden.
- Maximale Anzahl der zu crawlenden Seiten: Wenn Ihre Website über 24.000 Seiten verfügt, sollte die Einstellung nicht bei 10.000 Seiten, sondern 30.000 Seiten liegen.
Weitere Einstellungen
Falls es weiterhin Probleme gibt, prüfen Sie diese Einstellungen:
- Sitemap überprüfen: Aktivieren Sie die Option, Sitemaps zu crawlen.
- nofollow-Links: Aktivieren Sie das Folgen von nofollow-Links, wenn nötig.
- JavaScript Crawling aktivieren: Einige Webseiten laden Inhalte dynamisch per JavaScript. Aktivieren Sie JavaScript-Crawling, um alle URLs zu erfassen.











Keine Kommentare vorhanden